在所有声称提供R1服务的公司中,定价都远高于DeepSeek API,而且大多服务无法正常工作,吞吐量极低。
让大佬们震惊的是,一方面中国取得了这种能力,另一方面价格如此之低。(R1的价格,比o1便宜27倍)
训练便宜,为什么推理成本也这么低呢?
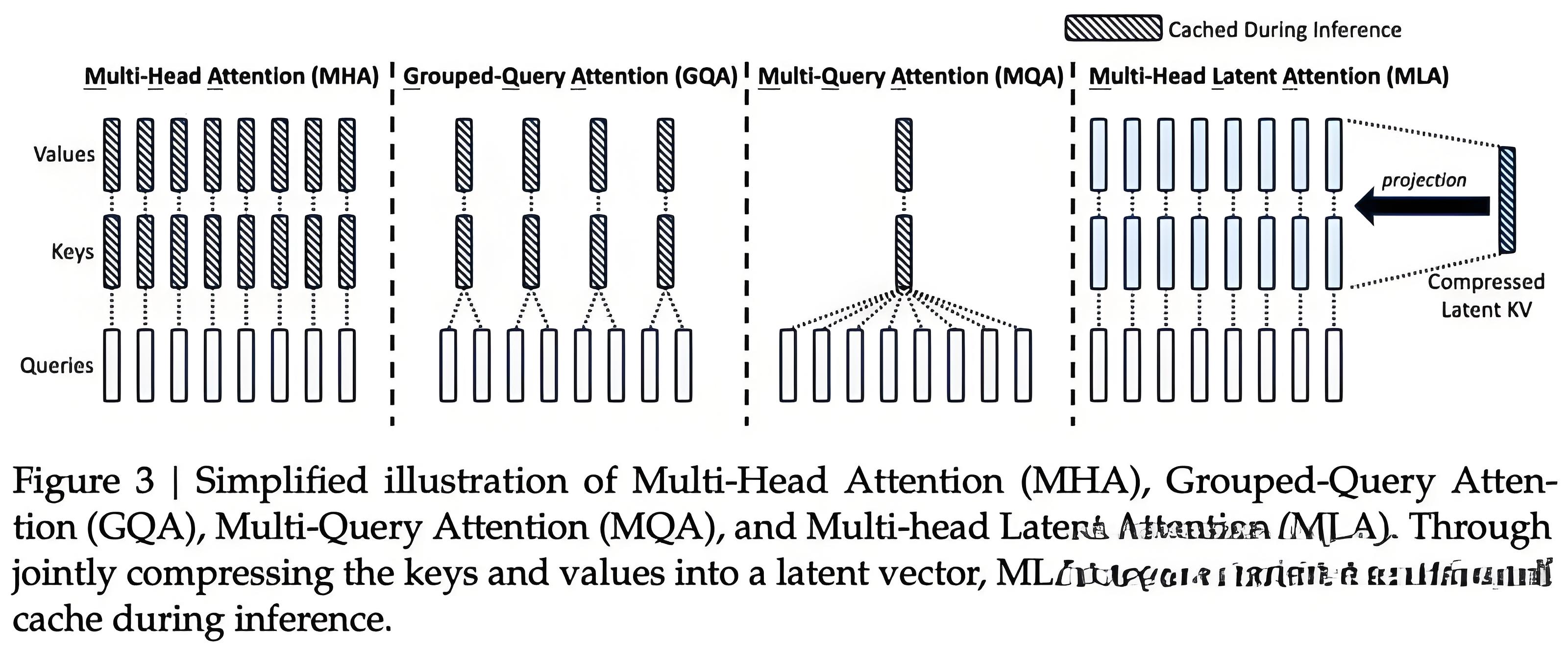
首先,就是DeepSeek在模型架构上的创新。MLA这种全新的注意力机制,跟Transformer注意力机制不同。
这种多头潜注意力,可以将注意力机制的内存占用减少大约80%到90%,尤其有助于处理长上下文。
而且,DeepSeek和OpenAI的服务成本有巨大差异,部分原因是OpenAI的利润率非常高,推理的毛利率超过了75%。
因为OpenAI目前是亏损的,在训练上花费了太多,因此推理的利润率很高。
接下来亮点来了,几位大佬放飞想象,猜测这会不会是一种阴谋论:DeepSeek精心策划了这次发布和定价,做空英伟达和美国公司的股票,配合星际之门的发布……
但这种猜测立马遭到了反驳,他们只是赶在农历新年前把产品尽快发布而已,并没有没有打算搞个大的,否则为什么选在圣诞节后一天发布V3呢?
中国的工业能力,已经远超美国
美国无疑在GPU等芯片领域领先于中国。
不过,对GPU出口管制,就能完全阻止中国吗?不太可能。
美国政府也清楚地认识到这一点, 而Nathan Lambert认为中国会制造自己的芯片。
中国可能拥有更多的人才、更多的STEM毕业生、更多的程序员。美国当然也可以利用世界各地的人才,但这未必能让美国有额外的优势。
真正重要的是计算能力。
中国拥有的电力总和,数量已经惊人。中国的钢铁厂,其规模相当于整个美国工业的总和,此外还有需要庞大电力的铝厂。
即使美国的星际之门真的建成,达到2吉瓦电力,仍小于中国最大的工业设施。
就这么说吧,如果中国建造世界上最大的数据中心,只要有芯片,马上就能做到。 所以这只是一个时间问题,而不是能力问题。
现在,发电、输电、变电站以及变压器等构建数据中心所需的东西,都将制约美国构建越来越大的训练系统,以及部署越来越多的推理计算能力。
相比之下,如果中国继续坚信Scaling Law,就像纳德拉、扎克伯格和劈柴等美国高管那样,甚至可以比美国更快地实现。
因此,为了减缓中国AI技术的发展,确保AGI无法被大规模训练,美国出台了一系列禁令——通过限制GPU、光刻机等关键要素的出口,意图「封杀」整个半导体产业。
OpenAI o3-Mini能追上DeepSeek R1吗?
接下来,几位大佬对几个明星推理模型进行了实测。
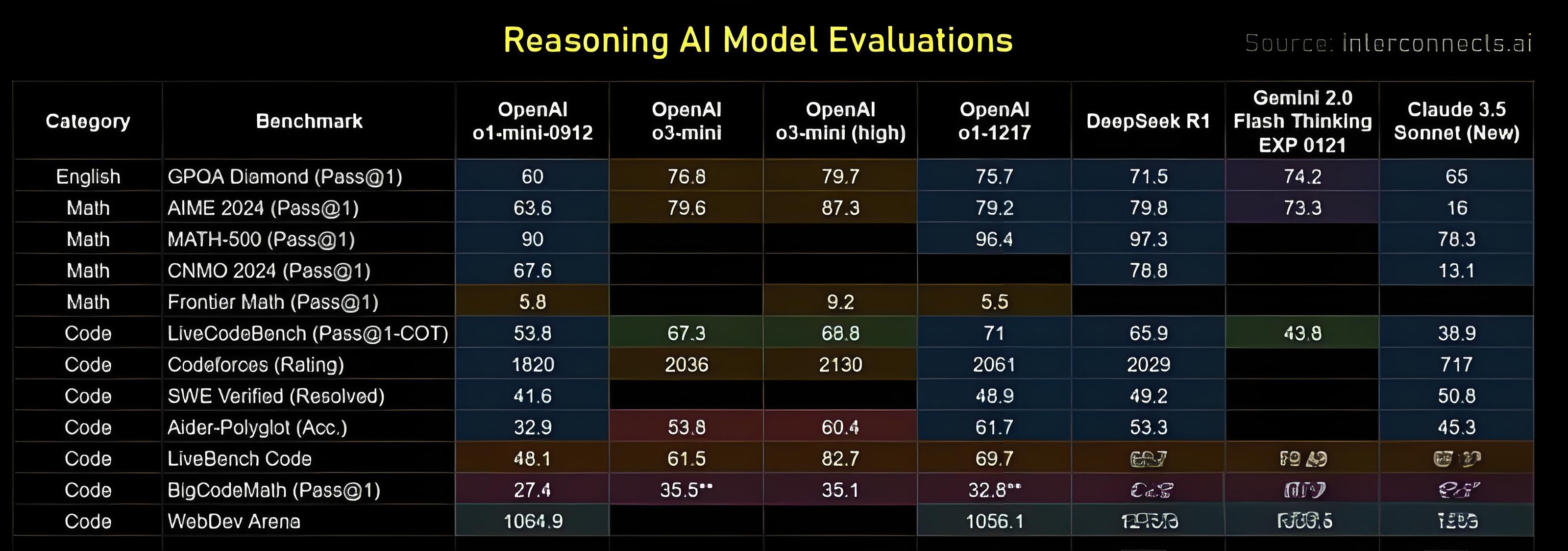
有趣的是,谷歌的Gemini Flash Thinking,无论从价格还是性能上来看都优于R1,而且在去年12月初就发布了,然而却无人关心……
对此,几位大佬的体感是,它的行为模式不如o1那样富有表现力,应用场景较窄。o1在特定任务上可能不是最完美,但灵活性和通用性更强。
Lex Frieman则表示,自己个人非常喜欢R1的一点,是它会展示完整的思维链token。
在开放式的哲学问题中,我们作为能欣赏智能、推理和反思能力的人类,阅读R1的原始思维链token,会感受到一种独特的美感。
这种非线性的思维过程,类似于詹姆斯·乔伊斯的意识流小说《尤利西斯》和《芬尼根的守灵夜》,令人着迷。
相比之下,o3-mini给人的感觉是聪明、快速,但缺乏亮点,往往比较平庸,缺乏深度和新意。
从下图中可以看到,从GPT-3到GPT-3.5,再到Llama,推理成本呈指数级下降趋势。
DeepSeek R1是第一个达到如此低成本的推理模型,这个成就很了不起,不过,它的成本水平并没有超出专家们预期的范围。
而在未来,随着模型架构的创新、更高质量的训练数据、更先进的训练技术,以及更高效的推理系统和硬件(比如新一代GPU和ASIC芯片),AI模型的推理成本还会持续下降。
最终,这将解锁AGI的潜力。





发表评论 取消回复