DeepSeek的成本涉及两项关键的技术:一个是MoE,一个就是MLA(多头潜注意力)。
MOE架构的优势在于,一方面,模型可以将数据嵌入到更大的参数空间中,另一方面,在训练或推理时,模型只需要激活其中一部分参数,从而大大提升效率。
DeepSeek模型拥有超过6000亿个参数,相比之下,Llama 405B有4050亿参数。从参数规模上看,DeepSeek模型拥有更大的信息压缩空间,可以容纳更多的世界知识。
但与此同时,DeepSeek模型每次只激活约370亿个参数。也就是说,在训练或推理过程中,只需要计算370亿个参数。相比之下,Llama 405B模型每次推理却需要激活4050亿个参数。
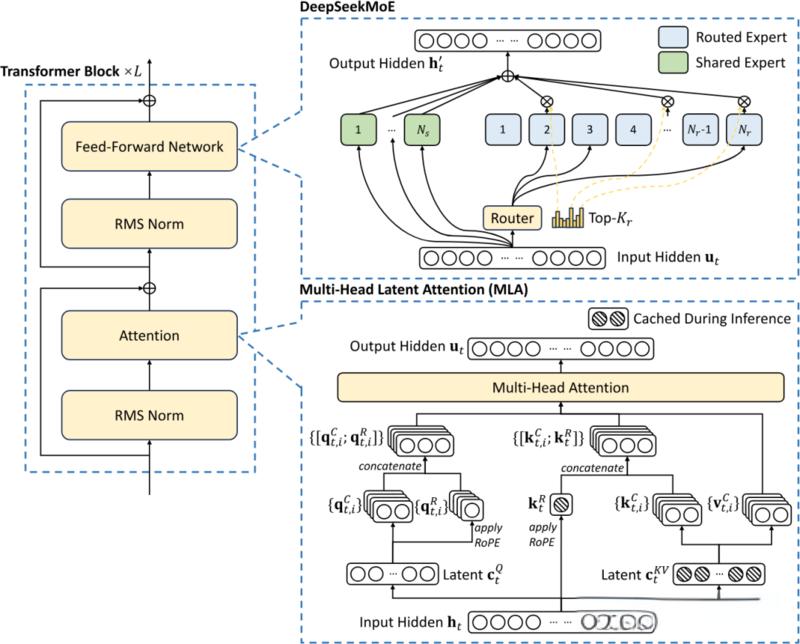
MLA主要用于减少推理过程中的内存占用,在训练过程也是如此,它利用了一些巧妙的低秩近似数学技巧。
深入研究潜注意力的细节,会发现DeepSeek在模型实现方面下了很大功夫。
因为,除了注意力机制,语言模型还有其他组件,例如用于扩展上下文长度的嵌入。DeepSeek采用的是旋转位置编码(RoPE)。
将RoPE与传统的MoE结合使用,需要进行一系列操作,例如,将两个注意力矩阵进行复数旋转,这涉及到矩阵乘法。
DeepSeek的MLA架构由于需要一些巧妙的设计,因此实现的复杂性大大增加。而他们成功地将这些技术整合在一起,这表明DeepSeek在高效语言模型训练方面走在了前沿。
DeepSeek想方设法提高模型训练效率。其中一个方法就是不直接调用NVIDIA的NCCL库,而是自行调度GPU之间的通信。
DeepSeek的独特之处在于,他们通过调度特定的SM(流式多处理器)来管理GPU通信。
DeepSeek会精细地控制哪些SM核心负责模型计算,哪些核心负责allreduce或allgather通信,并在它们之间进行动态切换。这需要极其高深的编程技巧。





发表评论 取消回复